高可用业务全链路监控方案
监控方案介绍
在 SRE 工程中,服务可观测性是一个重要的服务可靠性治理手段,其中包括但不限于:
- 服务器资源用量监测
- 服务状态及可用性指标监测
- 服务全链路跟踪监测
- 服务日志监测
- 报警、issues 闭环管理和事件通知系统
下面将分模块对服务业务全链路监控做一下规划以及介绍。
服务器资源和服务状态监测工具
在服务器资源和服务状态监测方面,我们经常使用 Zabbix、Prometheus、falcon 和夜莺等工具,但是在实际业务场景中更多的是使用 Prometheus,其原因有以下几点:
**Zabbix 不能很好的适用于云原生环境监控**。Zabbix 其优势在于有良好的 snmp、ipmi 和 jmx 等协议支持,但是对于云原生环境其扩展性和易用性相对较差(如在 k8s 环境中,其默认只能采集 node 的性能参数,对于 pod 性能参数以及业务指标等采集完全依赖于插件二次开发)。所以 zabbix 当今更多的是被用到监控网络设备等支持 snmp 和 ipmi 的设备场景。
**Falcon 和夜莺针对性过强**。Falcon 和夜莺都是云原生环境下的监控工具,但是这两种监控工具都是由国内厂商定制开发后放出的开源版本,其在某些特定领域可能有非常好的适配性,但是在通用场景下可能不是最优选择。
**Prometheus 是云原生环境下的标准监控工具**。Prometheus 是云原生环境下的标准监控工具,其优势在于有良好的可扩展性和易用性,同时支持插件化扩展,并且支持多种服务发现和指标采集方式,基本可以满足云原生业务和传统业务的监控需求。
Prometheus 在小型生产环境的应用
在小型生产环境中,特别在稳定性要求不是很高的场景中,通常只需要部署 Prometheus 服务端和 exporter 即可。其架构如下:
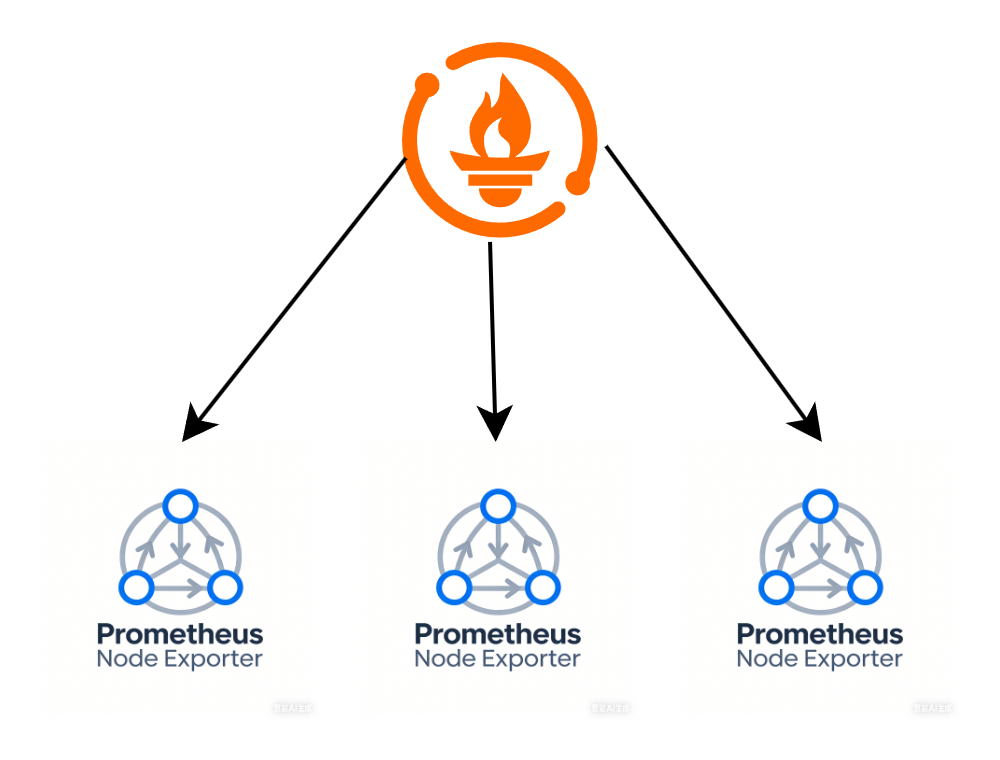
这是一个最简单的 prometheus 架构,在被监控节点中部署 exporter,然后 Prometheus 以 http 请求的方式从 exporter 暴露的 metrics 接口中采集指标。很明显,这样的架构在大型生产环境中,单机 Prometheus 无法满足大量 metrics 指标采集任务,所以需要设计另外的监控架构。
Prometheus 主动上报模式
在传统的 Prometheus 架构中,数据采集的压力完全被压到 Prometheus 服务端,其服务的负载会非常大,那么是否能将数据采集的压力分散到多个节点上去呢?当然可以。
Prometheus 提供了一个 PushGateway 方案,可以看这里PushGateway。在引入 PushGateway 后,数据采集架构变为如下:
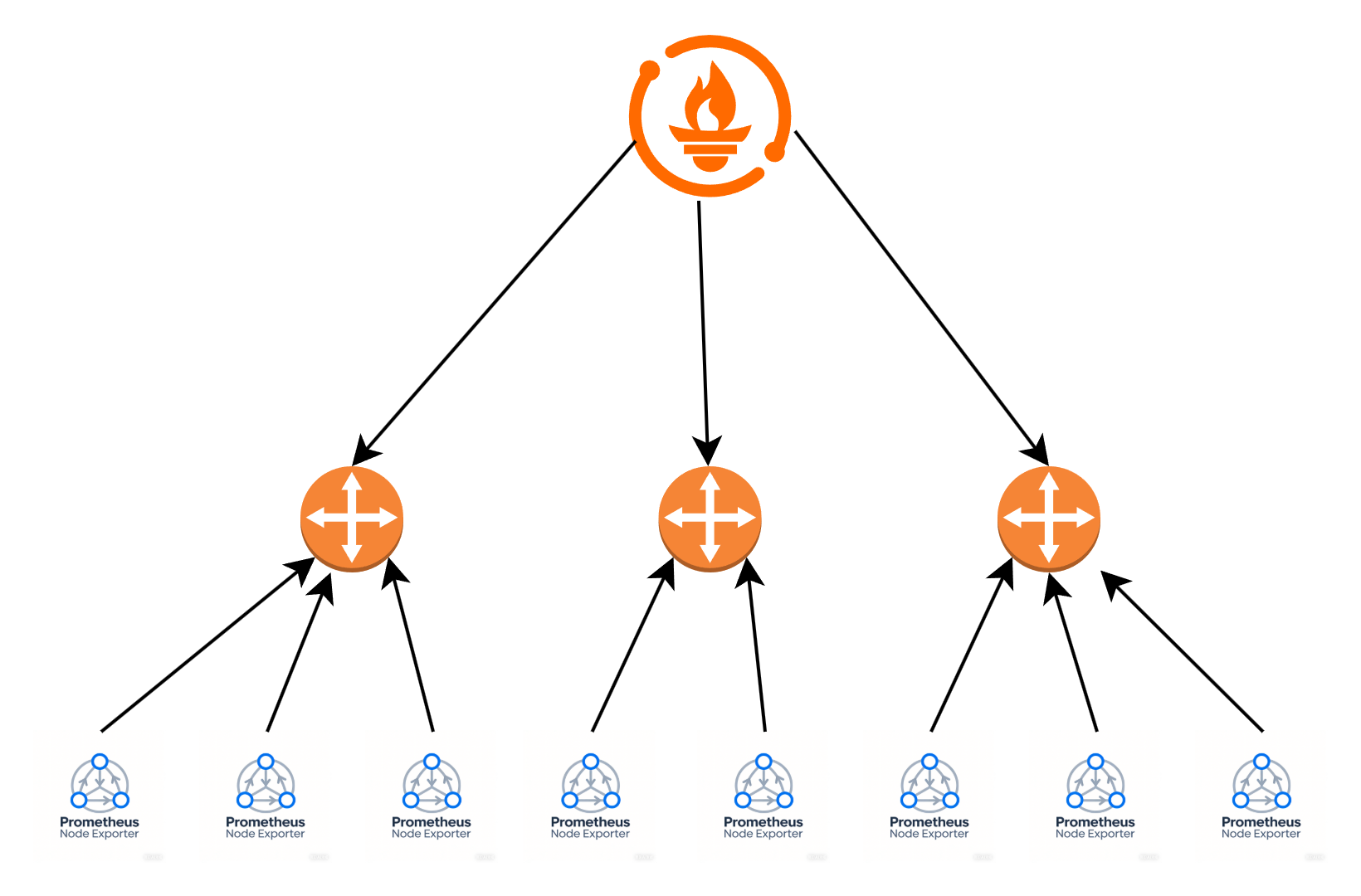
本方式仅适用于需要自主上报指标的场景,大部分的 exporter 基本基本都不支持基于 PushGateway 的指标上报,所以侧重于使用开源 exporter 采集指标需求的场景请绕道。
本架构体系中,其原理分为以下两部分:
- node 上,监控插件主动以 http 的方式向 PushGateway 上报指标,如
echo "some_metric 3.14" | curl --data-binary @- http://127.0.0.1:9091/metrics/job/some_job。上报后的指标由 PushGateway 进行暂存,并在 metrics 中进行暴露,如下:
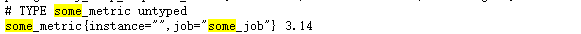
- Prometheus 服务端像在传统的 Prometheus 架构中一样,以 http 请求的方式从 PushGateway 暴露的 metrics 接口中采集指标。
不妨考虑一个问题
从上面的架构介绍里可以看到,不管是传统 Prometheus 架构还是 PushGateway 架构,都完全依赖于 http 请求,我们知道 http 请求有以下一些特点:
- 基于 TCP 协议,请求可靠,添加 https 后数据传输安全有保证。
- 在 http1.1 中,默认情况下,http 每发送一次请求都会和客户端构建一个连接。
但是这两个特点在监控场景下也许是非常致命的。试想一下,当下游节点数量过多时,即便 PushGateway 支持指标批量上报,在高并发上报场景下仍会出现连接数、文件描述符、处理队列等资源瓶颈,进而导致指标上报超时、丢弃甚至服务不可用。
已知在大部分场景下,监控数据的完整程度可能不那么重要(比如采样周期为 1min 的监控指标,可能丢失 1-2min 的监控数据或者数据有小范围的延迟也是可以容忍的,对全链路的观测性也是没要下降的),所以,我们可以把数据上报的方式用一种高效但是不那么可靠的方式——UDP。
试想一下如下的监控架构设计:
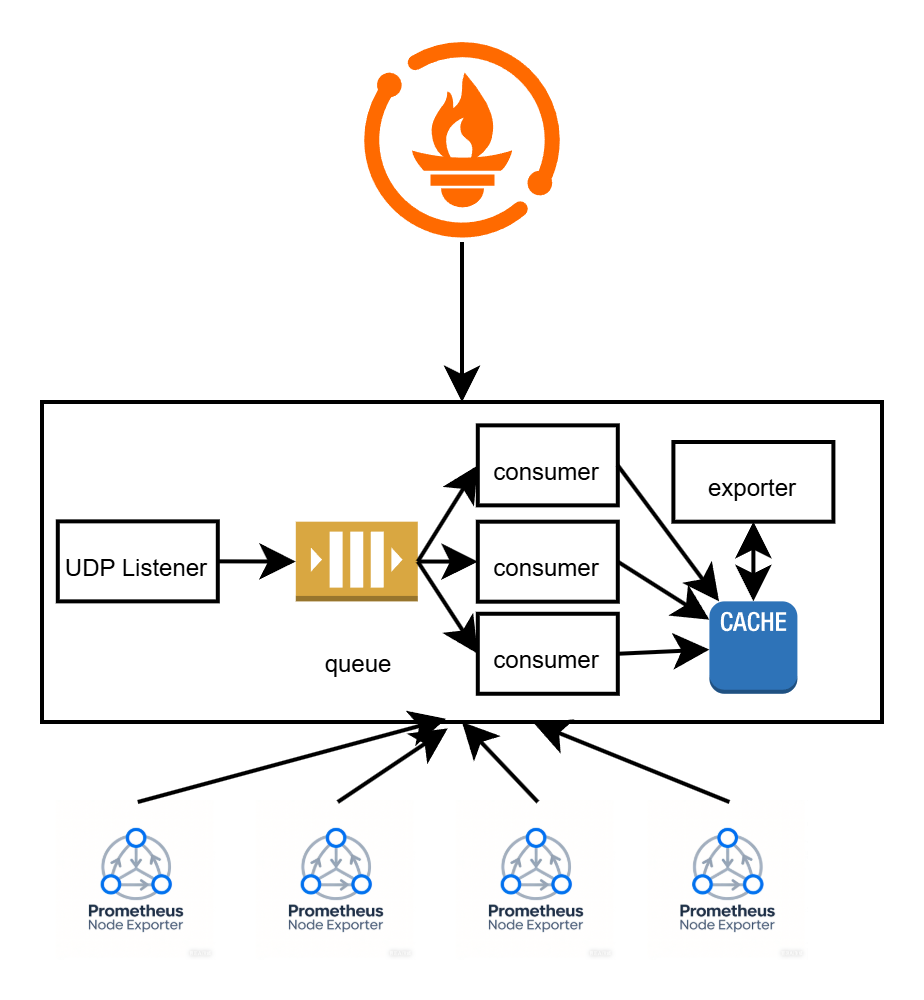
节点通过 UDP 的方式向中间服务报送数据,UDP Listener 接收到数据后写入到队列中,Consumer 消费队列中的数据,然后将数据写入到缓存中,再由一个 exporter 从缓存中读取数据,暴露为 metrics 接口。同时使用 Kubernetes Operator 定义一个 CRD,当队列中 Lag 超过阈值时自动增加 Consumer 的数量,保证监控数据即时落库。并配合 HPA,动态对 UDP Listener 进行扩缩容。
当然如果监控数据的完整度比较重要时,可以将 UDP Listener 换成类似 PushGateway 的 HTTP Listener。但是本方案的核心思想就是,数据上报和数据暴露分离,以确保数据代理节点的性能以及可靠性。
本方案目前无开源方案可用,运维团队可以根据自己的实际需求进行定制开发。
Prometheus 被动模式
其实在生产环境中更常用的是被动采集模式(就是 Prometheus+exporter 的模式),但是在大型生产环境中明显不能用 Prometheus 的经典架构,通常会引入 Prometheus 的联邦集群来采集压力分散,其架构图如下:
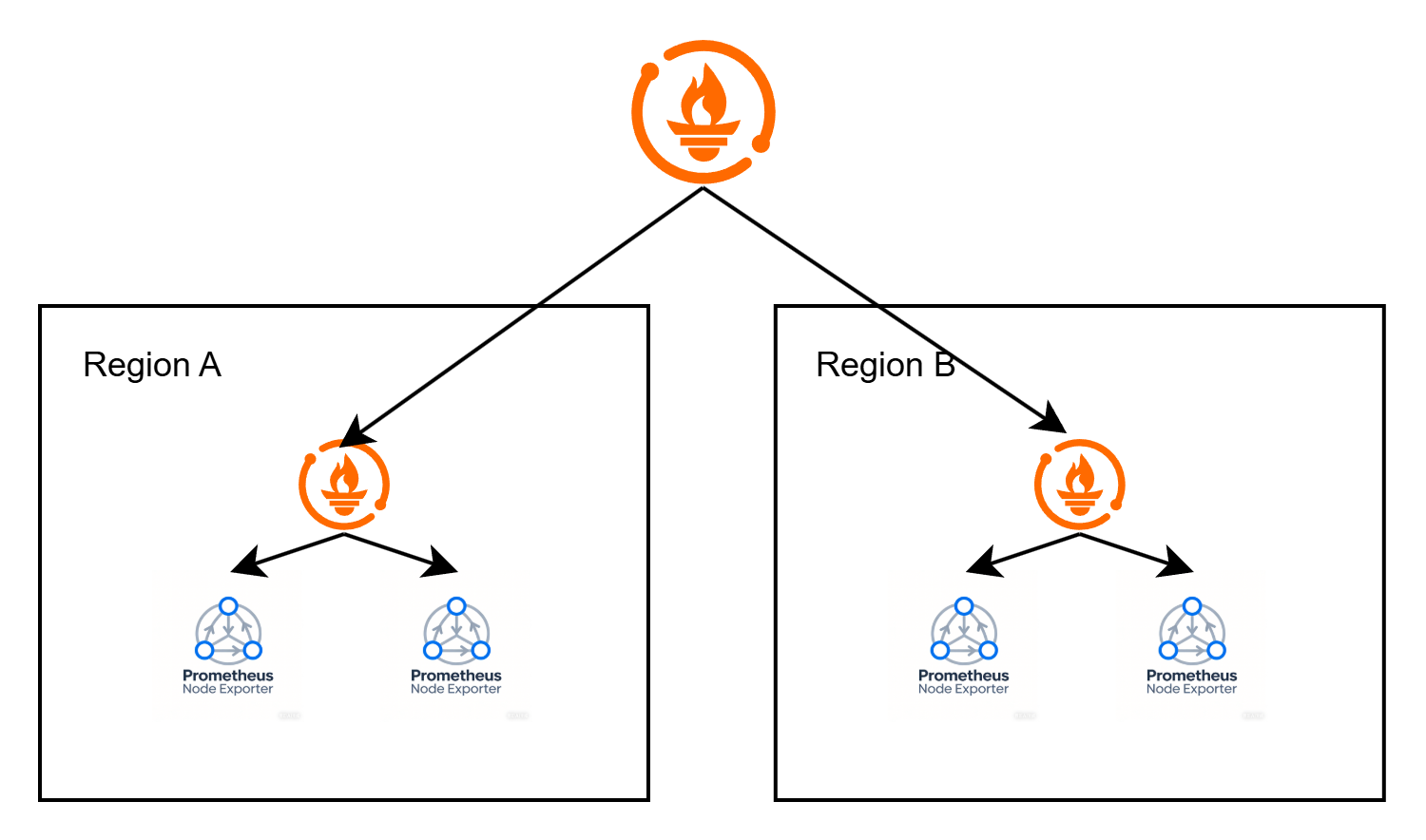
通俗的理解就是,将集群划分为 Region,每个 Region 中分别部署一套 Prometheus,从本 Region 中 node 上的 exporter 中采集指标。单独搭建一套核心 Prometheus,负责从所有 Region 的 Prometheus 中采集指标并汇总。
本方案的优点在于:
分 Region 部署,单 Region 的 Prometheus 出现故障时不会影响到全局异常。同时如果核心 Prometheus 出现故障时,扔可以直接从 Region 的 Prometheus 中查看本 Region 的监控数据。
核心 Prometheus 的指标采集压力分散到多个节点上去,虽然增加了监控的运维成本,但是保证了核心 Prometheus 的性能。
自动发现
在传统的 Prometheus 架构中,exporter 是需要注册到 prometheus.yaml 文件中的,虽然 Prometheus 目前已经支持了配置热重载,但是当大量节点需要导入时处理起来也是非常麻烦的。看到 Prometheus 官方文档有说到支持注册中心的目标群组,我们按照本方案进行一下自动化方案研讨。
目前开源的主流监控 exporter 基本都是不支持自动注册的,所以我们需要在 exporter 启动之前进行一次注册,可以直接使用以下脚本一键启动(以 node_exporter 为例)
1 |
|
在 prometheus 中修改配置使用 consul 自动发现:
1 | scrape_configs: |
在脚本运行时,首先会下载对应版本的 exporter,并且确保服务拉起后将服务注册到 consul 中,Prometheus 自动从 consul 中获取监控列表并进行采集。
针对于自研的 exporter 中,我们完全可以在插件中进行侵入式注册以确保全生命周期的管理(懒癌犯了,代码是 AI 生成的,如果有问题各位自行修正):
1 | SERVICE_ID = "" |
高可用
试想一个问题,Prometheus 的设计模式中,虽然可以实现服务与存储隔离强行实现分布式部署(如存储可以使用 influxdb 等时序性数据库),但是如果真的将 Prometheus 改成分布式,则会出现以下一些问题:
- 多个 Prometheus 服务端会执行一样的采集任务,可能会导致数据库中的指标数据重复。且如果用 influxdb 等中间件存储数据,可能会一个新的可用性工程层。
- 如果使用分片法让 Prometheus 采集指定分片的数据,那么某一节点故障一定会导致整个分片数据无法收集。
基于以上一些痛点,我们需要找一个能支持高可用的集群方案。
Thanos 是一个高可用的 Prometheus 集群方案,本质上来说是在 Prometheus 的上层实现了一个 sidecar,通过 sidecar 的方式优化了数据可用性与稳定性。其原理如下:
- Prometheus 的指标数据与中心节点分离,上传到 S3 存储中,确保数据不丢失。
- 多 Promethues 节点,数据仍会重复采集,但是在 Thanos 查询时会做去重。所以是以在存储用量上,遵循 N(节点数)*S(单机指标量)。
如果对存储成本比较介意的话,也可以使用Grafana Mimir。
Mimir 是 Prometheus 的一个远程存储的指标数据库,在多 Prometheus 副本的环境中,Mimir 会接收所有 Prometheus 的数据,只选取一个 active 的节点存入数据库,如果单点发生故障时,Mimir 监听数据上报时间超时,则会从其他节点中重新选出一个 active,并接收数据。这其实和主从集群有一些类似,但是和主从的区别在于,主从只有主才会写,而 mimir 是都会写。
服务性能全链路观测
在业务运营的过程中,往往需要一种手段对业务代码全链路的性能进行观测,包括但不限于:
- 服务调用链路
- 数据库查询链路
- 缓存查询链路
- 消息队列查询路
- 文件系统查询路
- 网络查询链路
目前最主流的方案是使用 Opentelemtry 的 SDK,并配合 Jaeger 等全链路观测平台进行全链路追踪。目前类似的追踪平台主要的数据上报方式都是 gRPC 和 HTTP,显然在大流量场景下有很大的瓶颈(如上报量太大时 Jaeger 阻塞,导致 span 上传失败)。
解决并发问题的终极奥义就是解耦
不管是 gRPC 还是 HTTP,虽然对于 SDK 来说都是异步上传,不阻塞主进程的,但是针对于 Jaeger 来说却都是同步请求。所以这里就需要将 Jaeger 收到的同步请求也转换为异步的。
解耦的第一步应该想到的就是队列,这里也不例外。可以将 Span 信息全部打到队列中,然后由一个 Consumer 异步消费 Span 并上报到 Jaeger 的 Collector 中。通过一些自定义 CRD 等的手段实现队列 Lag 和 Collector 性能监测和自动扩缩容。
当然,在服务应用本体直接对接到消息队列也不是一种很优雅的方式。其实我们可以基于 Opentelemtry 的 SDK 封装一套自用 SDK,将 Span 都以日志的形式落盘,然后再由 Filebeat 等组件将日志上传到消息队列中,其优势有以下几点:
- 多层次解耦,相当于给 Jaeger 加了多级缓存,保证 Jaeger 收集到的数据完整性和稳定性。
- Span 落盘,Trace 可回放。
其服务架构如下:
